
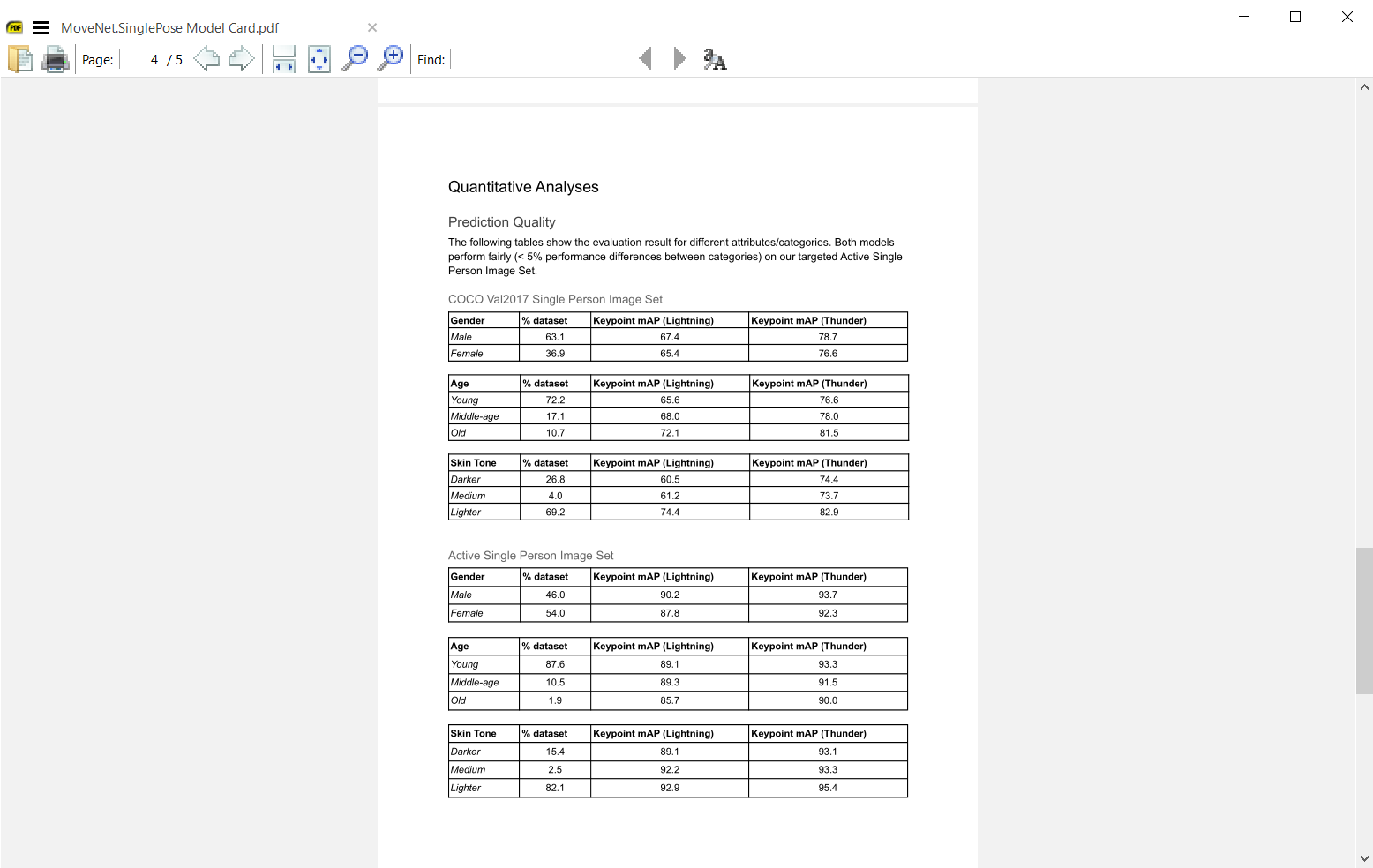
WQ1. How are AI-driven predictions made in high-stakes public contexts, and what social, organizational, and practical considerations must policymakers consider in their implementation and governance?
1Researchers are developing predictive systems to respond to contentious and complex public problems. These AI systems emerge across all types of domains, including criminal justice, healthcare, education and social services—high-stakes contexts that can impact quality of life in material ways. Which students do we think will succeed in college? Which defendants do we predict will turn up for a future court date? Who do we believe will benefit the most from a housing subsidy?
We know that the development of a predictive system in the real world is more than a technical project; it is a political one, and its success is greatly influenced by how a system is or is not integrated into existing decision-making processes, policies, and institutions. This integration depends on the specific sociological, economic and political context. To ensure that these systems are used responsibly when making high-impact decisions, it is essential to build a shared understanding of the types of sociotechnical challenges that recur across different real-world experiences. Understanding these processes should also help us build tools that effectively capture both human and machine expertise.
[1] This topic was the subject of a two-day workshop entitled “Prediction in Practice,” convened at Cornell Tech in June 2019. The workshop was organized by Cornell's AI, Policy, and Practice Initiative (AIPP), Upturn, and Cornell Tech’s Digital Life Initiative (DLI), with support from AI100, the John D. and Catherine T. MacArthur Foundation, and the Cornell Center for the Social Sciences. The discussion involved practitioners who had experience designing and implementing algorithmic systems in the public sector, as well as scholars from a wide range of disciplinary perspectives, ranging from computer science to anthropology, sociology, social work, psychology, philosophy, law, public policy, design, and beyond. The workshop was co-organized by Solon Barocas, Miranda Bogen, Jon Kleinberg, Karen Levy, Helen Nissenbaum, and David Robinson. More information on the event can be found at https://ai100.stanford.edu/sites/g/files/sbiybj9861/f/cornell_summary_report_public.pdf .Below are some core socio-technical considerations that scholars and practitioners should pay attention to over the next decade.
Problem Formalization
What problem is AI being used to solve? What is being predicted or optimized for, and by whom? Is AI the only or best way of addressing the problem before us? Are there other problems we might instead turn our attention to addressing? Which aspects of a problem can we address using AI, and which can’t we? The ways we define and formalize prediction problems shape how an algorithmic system looks and functions. Although the act of problem definition can easily be taken for granted as outside the purview of inquiry for AI practitioners, it often takes place incrementally as a system is built.2 In the best cases, it can be an opening for public participation, as the process of refining vague policy goals and assumptions brings competing values and priorities to the fore.3
Even subtle differences in problem definition can significantly change resulting policies. Tools used to apportion scarce resources like access to permanent housing can have quite different impacts depending on whether “need” is understood as the likelihood of future public assistance, the probability of re-entry into homeless services, or something else.4 In the context of financial subsidies for families to prevent income shocks, slightly different formalizations of the same policy goal can reverse the order in which families are prioritized to receive a subsidy.5
Problem definition processes must also stop short of assuming that a technical intervention is warranted in the first place.6 Technical solutions may themselves be part of the problem, particularly if they mask the root causes of social inequities and potential nontechnical solutions.7 The next generation of AI researchers and practitioners should be trained to give problem formalization critical attention. Meanwhile, practitioners might use their tools to study higher levels of the power hierarchy, using AI to predict the behaviors of powerful public-sector institutions and actors, not solely the least privileged among us.8
[2] Samir Passi and Solon Barocas, "Problem Formulation and Fairness," Proceedings of the ACM Conference on Fairness, Accountability, and Transparency (FAT* '19), January 2019 https://arxiv.org/abs/1901.02547v1
[3] Rediet Abebe, Solon Barocas, Jon Kleinberg, Karen Levy, Manish Raghavan, and David G. Robinson, "Roles for Computing in Social Change," Conference on Fairness, Accountability, and Transparency (FAT* ’20), January 2020 https://arxiv.org/pdf/1912.04883v4
[4] Halil Toros and Daniel Flaming, "Prioritizing Homeless Assistance Using Predictive Algorithms: An Evidence-Based Approach," Cityscape, Volume 20, No. 1, April 2018 https://socialinnovation.usc.edu/homeless_research/prioritizing-homeless-assistance-using-predictive-algorithms-an-evidence-based-approach/; Amanda Kube, Sanmay Das, and Patrick J. Fowler, "Allocating Interventions Based on Predicted Outcomes: A Case Study on Homelessness Services," Proceedings of the AAAI Conference on Artificial Intelligence, 2019 https://ojs.aaai.org//index.php/AAAI/article/view/3838
[5] Rediet Abebe, Jon Kleinberg, and S. Matthew Weinberg, "Subsidy Allocations in the Presence of Income Shocks," Proceedings of the AAAI Conference on Artificial Intelligence, 2020 https://ojs.aaai.org/index.php/AAAI/article/view/6188
[6] Andrew D. Selbst, Danah Boyd, Sorelle A. Friedler, Suresh Venkatasubramanian, and Janet Vertesi, "Fairness and Abstraction in Sociotechnical Systems," Proceedings of the Conference on Fairness, Accountability, and Transparency (FAT* '19), January 2019 https://dl.acm.org/doi/10.1145/3287560.3287598
[7] Rediet Abebe, Solon Barocas, Jon Kleinberg, Karen Levy, Manish Raghavan, and David G. Robinson, "Roles for Computing in Social Change," Conference on Fairness, Accountability, and Transparency (FAT* ’20), January 2020. https://arxiv.org/pdf/1912.04883v4.pdf
[8] Chelsea Barabas, Colin Doyle, JB Rubinovitz, and Karthik Dinakar, "Studying up: reorienting the study of algorithmic fairness around issues of power," Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency (FAT* '20), January 2020 https://dl.acm.org/doi/abs/10.1145/3351095.3372859
Integration, Not Deployment
We often use the term “deployment” to refer to the implementation of an AI system in the real world. However, deployment carries the connotation of implementing a more or less ready-made technical system, without regard for specific local needs or conditions. Researchers have described this approach as “context-less dropping in.”9 The most successful predictive systems are not dropped in but are thoughtfully integrated into existing social and organizational environments and practices. From the outset, AI practitioners and decision-makers must consider the existing organizational dynamics, occupational incentives, behavioral norms, economic motivations, and institutional processes that will determine how a system is used and responded to. These considerations become even more important when we attempt to make predictive models function equally well across different jurisdictions and contexts that may have different policy objectives and implementation challenges.
As in other algorithmic systems, the kinds of visible and invisible labor the system depends on are key concerns in public decision-making.10 Frontline workers—like judges, caseworkers, and law enforcement officers who interact directly with an algorithmic system—ultimately shape its effects, and developers must prioritize frontline workers’ knowledge and interests for integration to be successful. Resource constraints also matter: How will systems be maintained and updated over time?11 How can systems be made to correct course if they don’t work as expected? The answers to these questions depend on contextual social knowledge as much as technical know-how.
Collaborative design with stakeholders like frontline workers and affected communities can be a promising way to address these concerns, though it’s crucial to ensure that such participation is not tokenistic.12 Systems may also benefit when developers document both the social contexts in which a model is likely to perform successfully and the organizational and institutional processes that led to its development and integration. This practice borrows the logic of similar recent efforts to better document the data used to train machine-learning models as well as documenting the resulting models themselves. Formalizing these considerations might make it easier to determine whether a system can be easily adapted from one setting to another.
A heartbreaking example of how the integration process can go wrong is found in the use of AI to help treat patients with COVID-19. AI systems were among the first to detect the outbreak, and many research teams sprang into action to find ways of using AI technology to identify patterns and recommend treatments. Ultimately, these efforts were deemed unsuccessful as a combination of difficulty in sharing high quality data, a lack of expertise at the intersection of medicine and data science, and over optimism in the technology resulted in systems “not fit for clinical use.”
[9] https://datasociety.net/wp-content/uploads/2019/01/DataandSociety_AIinContext.pdf, page 9
[10] Mary L. Gray and Siddharth Suri, Ghost Work: How to Stop Silicon Valley from Building a New Global Underclass, Mariner Books, 2019 https://ghostwork.info; Mark Sendak, Madeleine Elish, Michael Gao, Joseph Futoma, William Ratliff, Marshall Nichcols, Armando Bedoya, Suresh Balu, Cara O’Brien, “'The Human Body is a Black Box': Supporting Clinical Decision- Making with Deep Learning," Proceedings of ACM Conference on Fairness, Accountability, and Transparency (FAT* 2020), January 2020 https://arxiv.org/pdf/1911.08089.pdf, Virginia Eubanks, Automating Inequality: How High-Tech Tools Profile, Police, and Punish the Poor, St. Martin's Press, 2018 https://virginia-eubanks.com/books/
[11] Karen Levy, Kyla E. Chasalow, and Sarah Riley, "Algorithms and Decision-Making in the Public Sector," Annual Review of Law and Social Science, Volume 17, 2021 https://arxiv.org/pdf/2106.03673.pdf
[12] Min Kyung Lee, Daniel Kusbit, Anson Kahng, Ji Tae Kim, Xinran Yuan, Allissa Chan, Daniel See, Ritesh Nooth- igattu, Siheon Lee, Alexandros Psomas, and Ariel D. Procaccia, "WeBuildAI: Participatory Framework for Algorithmic Governance," Proc. ACM Hum.-Comput. Interact. 3, CSCW, Article 181, November 2019 https://dl.acm.org/doi/pdf/10.1145/3359283;
Mona Sloane, Emanuel Moss, Olaitan Awomolo, and Laura Forlano, "Participation is not a Design Fix for Machine Learning," Proceedings of the 37th International Conference on Machine Learning, 2020 https://arxiv.org/abs/2007.02423v3, Anna Lauren Hoffmann, "Terms of inclusion: Data, discourse, violence," New Media & Society, September 2020 https://journals.sagepub.com/doi/abs/10.1177/1461444820958725?journalCode=nmsa
Diverse Governance Practices
Finally, new predictive technologies may demand new public-governance practices. Alongside the production of new technical systems, we need to consider what organizational and policy measures should be put in place to govern the use of such systems in the public sector. New proposals in both the US and the European Union exemplify some potential approaches to AI regulation.16
Appropriate measures may include establishing policies that govern data use—determining how data is shared or retained, whether it can be publicly accessed, and the uses to which it may be put, for instance—as well as standards around system adoption and procurement. Some researchers have proposed implementing algorithmic impact assessments akin to environmental impact assessments.17 Matters are further complicated by questions about jurisdiction and the imposition of algorithmic objectives at a state or regional level that are inconsistent with the goals held by local decision-makers.18
A related governance concern is how change will be managed: How, when, and by whom should systems be audited to assess their impacts?19 Should models be given expiration dates to ensure that they are not creating predictions that are hopelessly outdated? The COVID-19 pandemic is a highly visible example of how changing conditions invalidate models—patterns of product demands, highway traffic,20 stock market trends,21 emergency-room usage, and even air quality changed rapidly, potentially invalidating models trained on prior data about these dynamics.
The growth of facial-recognition technologies illustrates the diversity of governance strategies that states and municipalities are beginning to develop around AI systems. Current governance approaches range from accuracy- or agency-based restrictions on use, to process-oriented rules about training and procurement processes, to moratoria and outright bans.22 The diversity of approaches to governance around facial recognition may foreshadow how governments seek to address other types of AI systems in the coming decade.
Successfully integrating AI into high-stakes public decision-making contexts requires difficult work, deep and multidisciplinary understanding of the problem and context, cultivation of meaningful relationships with practitioners and affected communities, and a nuanced understanding of the limitations of technical approaches. It also requires sensitivity to the politics surrounding these high-stakes applications, as AI increasingly mediates competing political interests and moral commitments.
[16] https://www.ncsl.org/research/telecommunications-and-information-technology/2020-legislation-related-to-artificial-intelligence.aspx; Michael Veale and Frederik Zuiderveen Borgesius, “Demystifying the Draft EU Artificial Intelligence Act,” SocArXiv, 6 July 2021 https://osf.io/preprints/socarxiv/38p5f
[17] Andrew D. Selbst, "Disparate Impact in Big Data Policing", Georgia Law Review, Number 109, 2018 https://www.georgialawreview.org/article/3373-disparate-impact-in-big-data-policing; Jacob Metcalf, Emanuel Moss, Elizabeth Anne Watkins, Ranjit Singh, and Madeleine Clare Elish, "Algorithmic Impact Assessments and Accountability: The Co-construction of Impacts," Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT '21), 2021 https://dl.acm.org/doi/abs/10.1145/3442188.3445935
[18] Alicia Solow-Niederman, YooJung Choi, and Guy Van den Broeck, "The Institutional Life of Algorithmic Risk Assessment," Berkeley Tech. L.J., 2019 http://starai.cs.ucla.edu/papers/Solow-NiedermanBTLR19.pdf
[19] https://www.adalovelaceinstitute.org/report/examining-the-black-box-tools-for-assessing-algorithmic-systems/
[20] https://blog.google/products/maps/google-maps-101-how-ai-helps-predict-traffic-and-determine-routes
[21] https://www.nytimes.com/2020/04/02/business/stock-market-predictions-coronavirus-shiller.html
[22] https://ainowinstitute.org/regulatingbiometrics-spivack-garvie.pdf
Cite This Report
Michael L. Littman, Ifeoma Ajunwa, Guy Berger, Craig Boutilier, Morgan Currie, Finale Doshi-Velez, Gillian Hadfield, Michael C. Horowitz, Charles Isbell, Hiroaki Kitano, Karen Levy, Terah Lyons, Melanie Mitchell, Julie Shah, Steven Sloman, Shannon Vallor, and Toby Walsh. "Gathering Strength, Gathering Storms: The One Hundred Year Study on Artificial Intelligence (AI100) 2021 Study Panel Report." Stanford University, Stanford, CA, September 2021. Doc: http://ai100.stanford.edu/2021-report. Accessed: September 16, 2021.
Report Authors
AI100 Standing Committee and Study Panel
Copyright
© 2021 by Stanford University. Gathering Strength, Gathering Storms: The One Hundred Year Study on Artificial Intelligence (AI100) 2021 Study Panel Report is made available under a Creative Commons Attribution-NoDerivatives 4.0 License (International): https://creativecommons.org/licenses/by-nd/4.0/.